
如果你最近想体验“本地 AI 工作流”这件事,但又不想自己从 n8n、Ollama、Qdrant、PostgreSQL 一路手搓到怀疑人生,那
n8n self-hosted-ai-starter-kit基本就是现成答案。
这篇文章就走最务实的路线:用 Docker Compose 把整套环境拉起来,跑通官方内置工作流,并验证服务是否正常可用。先跑通,再谈花活。
官方 GitHub的项目地址:

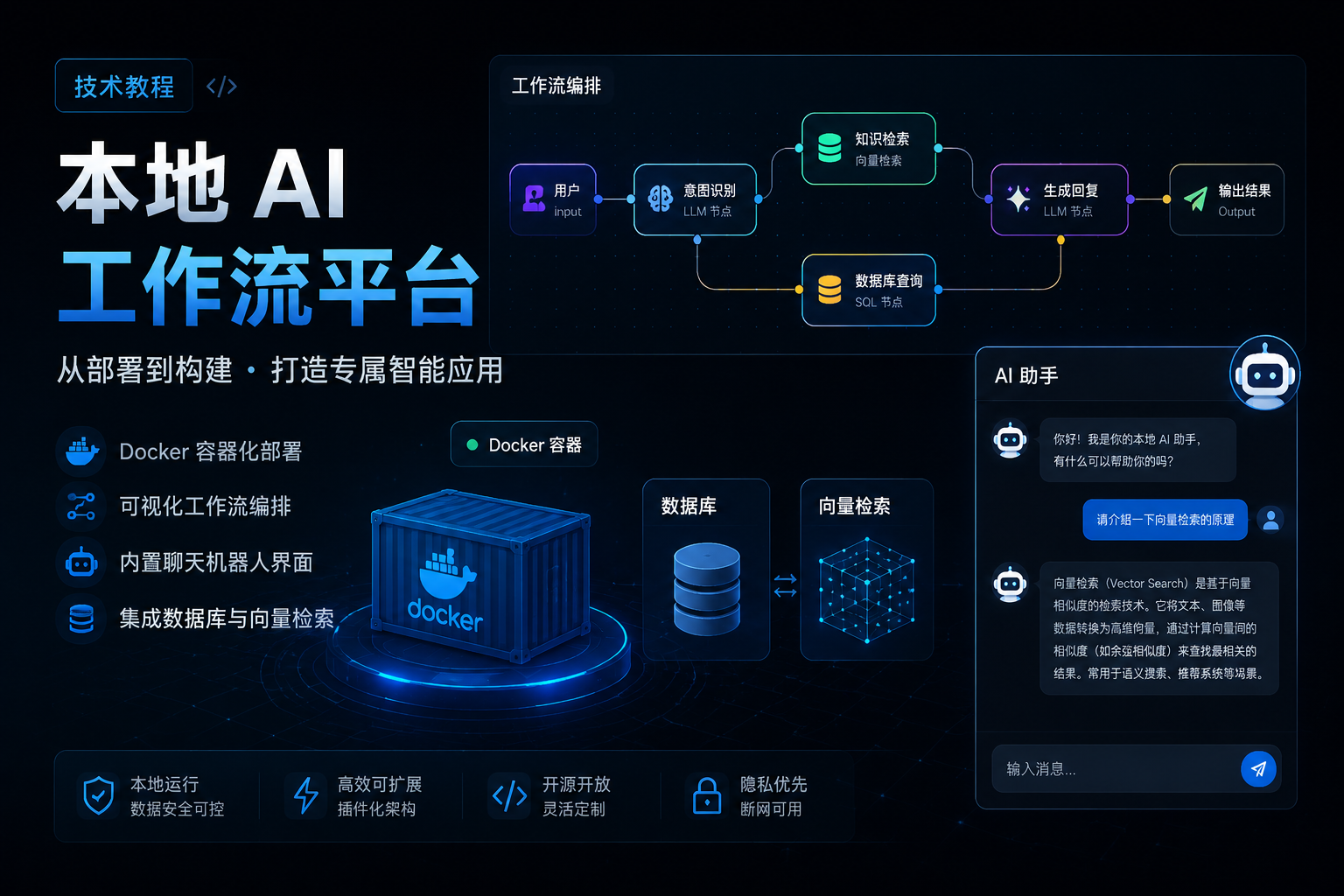
n8n self-hosted-ai-starter-kit 是 n8n 官方提供的一套 自托管 AI 工作流启动模板。它的目标非常直接:用一份 Docker Compose 配置,把一套本地 AI 自动化环境快速搭起来。
这套 Starter Kit 主要包含以下组件:
- n8n:低代码工作流平台,支持 400+ 集成和 AI 节点
- Ollama:本地大模型运行平台
- Qdrant:向量数据库
- PostgreSQL:n8n 的持久化数据库
它适合的场景也很明确:
- 想本地体验 AI 工作流编排
- 想搭建私有化 AI 自动化环境
- 想研究 n8n + LLM + 向量库 的基本组合
- 想先跑通 PoC,再考虑生产化改造
为什么这个项目值得写成安装部署教程?
因为它不像很多“AI 大项目”那样一上来就把门槛抬到天上去。它的主路径比较清晰,官方 README 也给了明确启动方式,非常适合写成一篇“普通开发者能照着跑”的实操文。
本文采用的是最稳妥、最容易复现的 CPU 简化方案。
- 操作系统:Ubuntu 22.04 / 24.04 或其他 Linux 发行版
- Docker:建议
24.x及以上 - Docker Compose:建议
v2.x - Git:任意较新版本
- 部署方式:Docker Compose
- 硬件要求:
- 最低建议:4 核 CPU、8GB 内存
- 更推荐:8 核 CPU、16GB 内存
- 是否为简化方案:是
因为 GPU 方案虽然更快,但也更容易翻车:
- NVIDIA 方案依赖 Docker GPU Runtime
- AMD 方案依赖 ROCm
- Mac 上 Docker 容器又不能直接吃 Apple Silicon GPU
所以这篇文章优先带你走:
先用 CPU 方式把环境拉起来,确认整套链路能跑。
等你确认没问题,再切 GPU,不迟。
先确认本机已经安装好 Docker。
docker --version
docker compose version
如果能正常输出版本号,说明基础环境没问题。
如果还没装,可以先参考 Docker 官方文档安装。这里就不展开了,毕竟本文重点不是“手把手装 Docker”。
执行下面命令:
git clone https://github.com/n8n-io/self-hosted-ai-starter-kit.git
cd self-hosted-ai-starter-kit
进入目录后,建议先看一下文件结构,大致会包含:
docker-compose.yml.env.examplen8n/demo-data/shared/(运行后会作为共享目录使用)
项目使用 .env 文件注入关键配置。可以直接复制官方示例:
cp .env.example .env
官方 .env.example 里默认包含这些配置:
POSTGRES_USER=root
POSTGRES_PASSWORD=password
POSTGRES_DB=n8n
N8N_ENCRYPTION_KEY=super-secret-key
N8N_USER_MANAGEMENT_JWT_SECRET=even-more-secret
N8N_DEFAULT_BINARY_DATA_MODE=filesystem
虽然你本地测试用默认值也能跑,但至少把这两个密钥改一下,别图省事一路默认:
N8N_ENCRYPTION_KEY=replace-with-your-own-secret-key
N8N_USER_MANAGEMENT_JWT_SECRET=replace-with-your-own-jwt-secret
你可以简单一点,自己生成随机字符串,比如:
openssl rand -hex 16
openssl rand -hex 16
这个项目默认会用到以下端口:
5678:n8n Web 界面11434:Ollama6333:Qdrant
如果这些端口已经被占用,启动时大概率会直接报错。
可以提前检查:
ss -lntp | grep -E '5678|11434|6333'
如果发现被占用,要么停掉原服务,要么改 docker-compose.yml 里的端口映射。

这一节是主线,按顺序来。
为了减少“启动时卡半天不知道死哪了”的体验,建议先手动拉镜像:
docker compose --profile cpu pull
这一步会拉取:
n8nio/n8n:latestpostgres:16-alpineqdrant/qdrantollama/ollama:latest
如果网络环境一般,这一步可能比较慢,尤其是 Ollama 镜像和后续模型拉取。别急,这类项目慢是常态,不是你电脑在和你作对。
CPU 模式启动命令如下:
docker compose --profile cpu up
如果你希望后台运行,可以加 -d:
docker compose --profile cpu up -d
根据官方 docker-compose.yml,主要包括:
postgresn8n-importn8nqdrantollama-cpuollama-pull-llama-cpu
其中有两个点需要特别说明:
这个容器会在首次启动时自动导入示例工作流和凭据。
如果已经存在工作流,它会跳过导入。
这个容器会执行:
ollama pull llama3.2
也就是说,首次启动不只是起容器,还会自动拉取 Llama 3.2 模型。
如果你看到服务起来了,但工作流一时半会儿跑不动,很多时候不是项目坏了,是模型还没下完。
如果不是后台启动,可以直接在当前终端看日志。
如果是后台启动,建议单独开一个终端查看:
docker compose logs -f
你重点关注几个服务:
docker compose logs -f n8n
docker compose logs -f postgres
docker compose logs -f qdrant
docker compose logs -f ollama-cpu
如果看到类似下面的信息,说明 n8n 基本启动完成:
Editor is now accessible via: http://localhost:5678/
打开浏览器访问:
http://localhost:5678/
第一次进入时,n8n 会要求你完成初始化设置。这个过程通常只需要做一次,比如:
- 创建管理员账号
- 设置登录信息
- 进入工作台
完成后,就可以正常使用 n8n 界面了。
这个 Starter Kit 的优点是:默认配置已经够你先跑通。
所以这一节不用搞得太重,抓关键点就行。
这是整个项目的主配置文件,定义了所有服务、网络、卷、端口和 profile。
这是你最需要关注的配置文件,主要影响:
- PostgreSQL 账号密码
- n8n 加密密钥
- JWT Secret
- Ollama 主机地址
用于 PostgreSQL 初始化。
n8n 会通过这些变量连接数据库。
n8n 用来加密敏感数据。
这个值建议固定,后续不要随意改,不然历史凭据可能解不开。
用户管理相关的 JWT 密钥。
同样建议首次确定后长期保持一致。
默认值来自 docker-compose.yml:
OLLAMA_HOST=${OLLAMA_HOST:-ollama:11434}
这意味着:
- 默认走 Compose 网络中的 Ollama 容器
- 如果你想改成宿主机上的 Ollama,可以在
.env里覆盖
例如 Mac 上本地运行 Ollama 时,官方建议写:
OLLAMA_HOST=host.docker.internal:11434
官方说明中提到,项目会挂载一个共享目录到 n8n 容器:
- 宿主机目录:
./shared - 容器内路径:
/data/shared
如果你的工作流需要读取本地文件、上传 PDF、做知识库导入,这个路径很有用。
在 n8n 节点里访问本地文件时,请用容器内路径 /data/shared,不是你宿主机上的绝对路径。
这个地方非常容易搞错。
部署成功不算完,能跑起来一个最小闭环才算真的完成。

官方 README 给了一个内置工作流地址:
http://localhost:5678/workflow/srOnR8PAY3u4RSwb
在浏览器中打开它。
如果你是首次启动,n8n-import 正常执行的话,这个工作流应该已经被导入。
由于 Starter Kit 会自动拉取 llama3.2,所以先检查 Ollama 是否准备就绪。
查看日志:
docker compose logs -f ollama-pull-llama-cpu
或者进入 Ollama 容器检查模型列表:
docker exec -it ollama ollama list
如果你能看到类似:
llama3.2
说明模型已经到位。
官方说明里提到,在工作流画布底部点击 Chat 按钮,就可以开始运行这个 AI 工作流。
正常情况下,你应该能看到:
- 工作流被成功触发
- 聊天输入后有模型返回结果
- n8n 执行链路中节点出现运行状态
- 如果涉及向量检索,Qdrant 也会参与处理
如果你点击后长时间没响应,先别急着怀疑人生,通常优先排查这几件事:
llama3.2是否还在下载ollama容器是否正常运行n8n是否已正确导入工作流- 机器内存是否过低导致服务卡住
如果你后续想测试“本地文件 + AI 工作流”,可以把文件放到项目根目录下的:
./shared
然后在 n8n 节点中用容器路径访问:
/data/shared/你的文件名.pdf
这也是这套 Starter Kit 比较实用的一点:文件链路已经给你预留好了。
部署是否成功,不要只看“容器启动了没”,最好至少做 3 层验证。
docker compose ps
理想状态下,你应该看到主要服务处于 Up 状态,例如:
postgresn8nqdrantollama
如果某个关键服务反复重启,说明不是“稍等就好”,而是配置、依赖或资源有问题。
访问:
http://localhost:5678/
如果你能看到 n8n 界面并成功登录,说明:
n8n服务正常5678端口映射正常- 前端访问链路正常
执行:
docker exec -it ollama ollama list
如果能列出 llama3.2 或其他模型,说明 Ollama 正常。
你也可以看日志:
docker compose logs -f ollama-cpu
Qdrant 默认暴露 6333 端口,可以简单确认端口监听:
ss -lntp | grep 6333
如果服务运行正常,一般说明向量库容器已起来。
登录 n8n 后,在工作流列表里确认是否已存在官方导入的示例工作流。
如果没有,重点检查 n8n-import 容器日志:
docker compose logs n8n-import
如果这里导入失败,后面 Demo 跑不起来就很正常,不用甩锅给 AI。
这一节比较重要。很多时候真不是项目有问题,而是环境、端口、资源、网络这几个老熟人在搞事。

启动时报类似错误:
Bind for 0.0.0.0:5678 failed: port is already allocated
或者 11434、6333 被占。
先查占用进程:
ss -lntp | grep -E '5678|11434|6333'
然后:
- 停掉冲突服务
- 或修改
docker-compose.yml中的端口映射
例如把 n8n 改成:
ports:
- 5679:5678
改完后访问地址也要对应调整成:
http://localhost:5679/
docker compose pull
卡住,或者 ollama pull llama3.2 非常慢。
- 先确认 Docker 网络可用
- 必要时为 Docker 配置镜像加速
- 模型下载阶段耐心一点,尤其首次拉取别指望秒下完
- 可以单独查看 Ollama 拉模日志:
docker compose logs -f ollama-pull-llama-cpu
这类问题十有八九是网络,不是 Compose 文件在故意整你。
示例工作流没有出现,或者日志报导入错误。
先看日志:
docker compose logs n8n-import
排查重点:
postgres是否已经健康n8n-import是否在postgres可用前就启动异常./n8n/demo-data目录是否存在且内容完整
必要时可以重新创建容器:
docker compose down
docker compose --profile cpu up
如果是已有工作流导致跳过导入,这属于正常逻辑,不是故障。
界面能进,但 Chat 没反应,或者执行很慢。
优先按这个顺序查:
- 模型是否已经下载完成
docker exec -it ollama ollama list
- Ollama 容器是否正常
docker compose ps
docker compose logs -f ollama-cpu
-
机器资源是否不足
尤其是内存不够时,AI 相关组件卡住非常常见。 -
OLLAMA_HOST是否配置正确
特别是 Mac 用户如果 Ollama 跑在宿主机,不改这个地址基本白搭。
n8n 日志里出现数据库连接错误,服务反复重启。
检查 .env 中这几个变量是否一致:
POSTGRES_USER=...
POSTGRES_PASSWORD=...
POSTGRES_DB=...
再确认 docker-compose.yml 里 n8n 读取的是:
DB_TYPE=postgresdb
DB_POSTGRESDB_HOST=postgres
DB_POSTGRESDB_USER=${POSTGRES_USER}
DB_POSTGRESDB_PASSWORD=${POSTGRES_PASSWORD}
如果你改过变量名或手误拼错,n8n 连不上库是必然的。
这种问题不用重装系统,先检查自己写的配置,效率更高。
n8n 能开,但调用本机 Ollama 失败。
如果你是在 Mac 宿主机本地运行 Ollama,而不是容器内运行,官方建议修改 .env 或 Compose 中相关配置,让 n8n 指向:
OLLAMA_HOST=host.docker.internal:11434
同时在 n8n 的凭据页面里,把 Local Ollama service 的 Base URL 改成:
http://host.docker.internal:11434/
这个问题很常见,本质就是容器访问宿主机地址不对。
docker compose ps
看到某些服务不断 Restarting。
先不要条件反射式地 docker rm -f $(docker ps -aq),那是情绪发泄,不是排障。
正确姿势是逐个看日志:
docker compose logs --tail=100 n8n
docker compose logs --tail=100 postgres
docker compose logs --tail=100 ollama-cpu
docker compose logs --tail=100 qdrant
重点排查:
- 环境变量缺失
- 端口冲突
- 数据卷权限问题
- 机器内存不足
- GPU profile 用错
如果你已经跑通这套 Starter Kit,后面可以继续往这些方向深入:
官方支持:
--profile gpu-nvidia--profile gpu-amd
如果你机器条件允许,GPU 推理速度会明显更好。
但部署复杂度也会上去,建议在 CPU 路线稳定后再尝试。
特别是 Mac 用户,宿主机直跑 Ollama 往往更现实。
这时只需要把 OLLAMA_HOST 指向宿主机地址。
官方 README 里还给了不少 AI 模板方向,比如:
- Chat with PDF docs
- Web 抓取 Agent
- Financial Documents Assistant
- Qdrant + Mistral 场景
你可以从 n8n AI 模板库继续导入工作流做扩展。
这套 Starter Kit 官方也明确说了:更偏 PoC 和快速启动,不是完整生产方案。
如果要上生产,至少要补这些东西:
- 固定镜像版本
- 反向代理与 HTTPS
- 持久化存储规划
- 备份策略
- 资源监控
- 安全配置
到这里,你已经完成了这套 n8n self-hosted-ai-starter-kit 的核心部署流程:
- 拉取项目代码
- 配置
.env - 用 Docker Compose 启动 CPU 版环境
- 访问 n8n Web 界面
- 检查 Ollama / Qdrant / PostgreSQL 状态
- 跑通官方内置工作流
这套项目最大的价值,不是“功能多到看不完”,而是它把一套本地 AI 工作流的基础拼图先给你搭好了。
对于普通开发者来说,先把环境跑起来、知道每个组件在干什么、能触发第一个 AI 工作流,这一步其实就已经很值了。
后面你要不要继续折腾知识库、Agent、自动化审批、文档分析,那是下一阶段的故事。先跑通,先别和环境置气。
这套项目尤其适合下面几类读者继续研究:
- 想做 AI 工作流自动化的开发者
- 想体验私有化本地 AI 编排环境的工程师
- 想研究 n8n AI 节点能力的技术人员
- 准备把 PoC 演进成团队内部工具的项目组
- 想基于 n8n 做二次开发或业务集成的团队
如果你只是想体验一下“本地 AI 工作流是怎么串起来的”,跑到本文这一步已经够用。
如果你要做生产部署,那就得继续补安全、稳定性和资源管理这几课。
你更想看哪类 GitHub 项目部署教程?










暂无评论内容